Let’s GOSSIP软件安全暑期学校笔记
DAY 2: 7.21
今日演讲主题:
- 机器学习安全吗?挖掘ML Model中的隐私和安全问题 张阳
- 语言理解之美——基于NLP的漏洞分析 王健强
ML Module中的隐私和安全问题 张阳
张阳老师首先介绍了CISPA的基本情况。
背景:机器学习大热
最近发现机器学习模型存在大量隐私问题。
五个方向的内容:
- Privacy
- Membership inference
Attack 1
训练Attack Module,可以判断熊猫是否在训练集中:
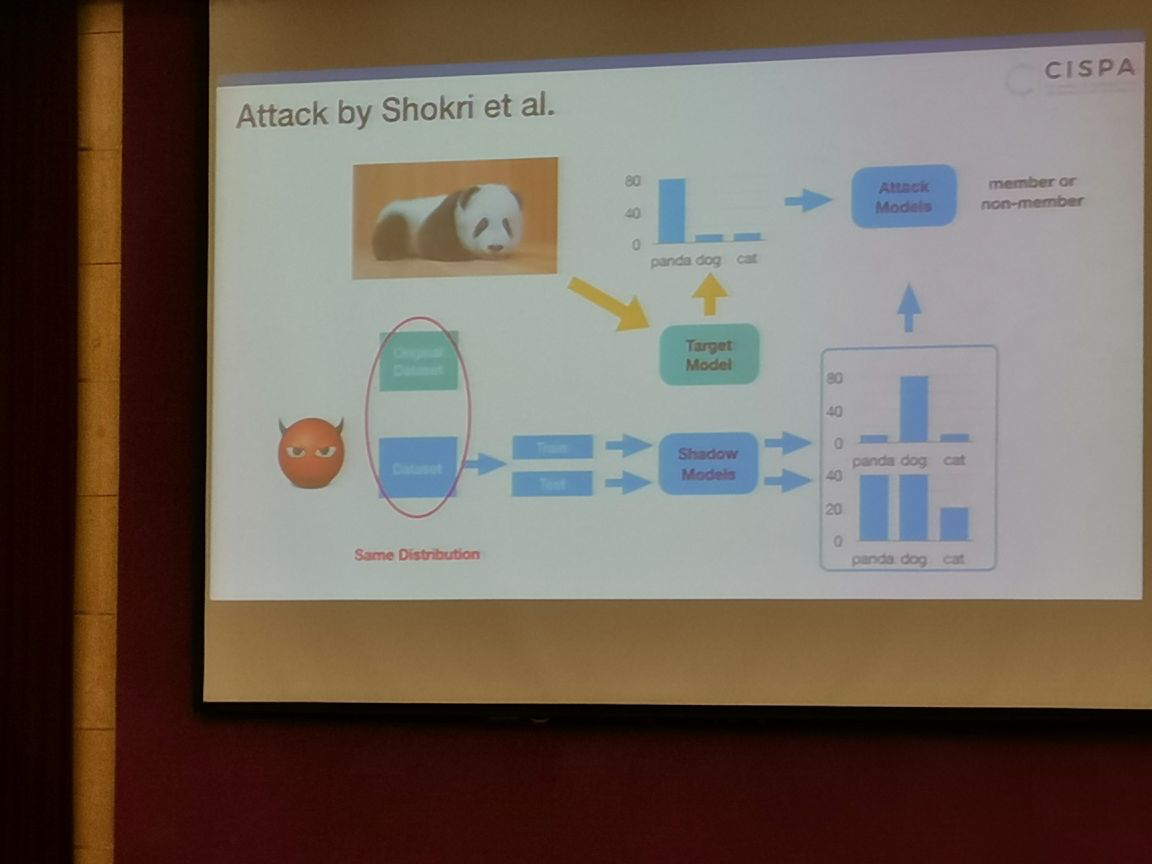
攻击成功的原因:过拟合。因为机器学习在遇到训练过的样本时会更加的“自信”
过拟合程度越高,攻击模型表现越好。
Attack 2
解决样本集合同分布的问题
Attack 3
不用构建任何数据集,选一个阈值,超过即确定。
防御:
减少过拟合。
- Data reconstruction
attack surface in online learning
在线学习更新后,通过同一张图片得到不同后验概率。如此反复,逆向工程推断出更新的数据集。
general attack pipeline
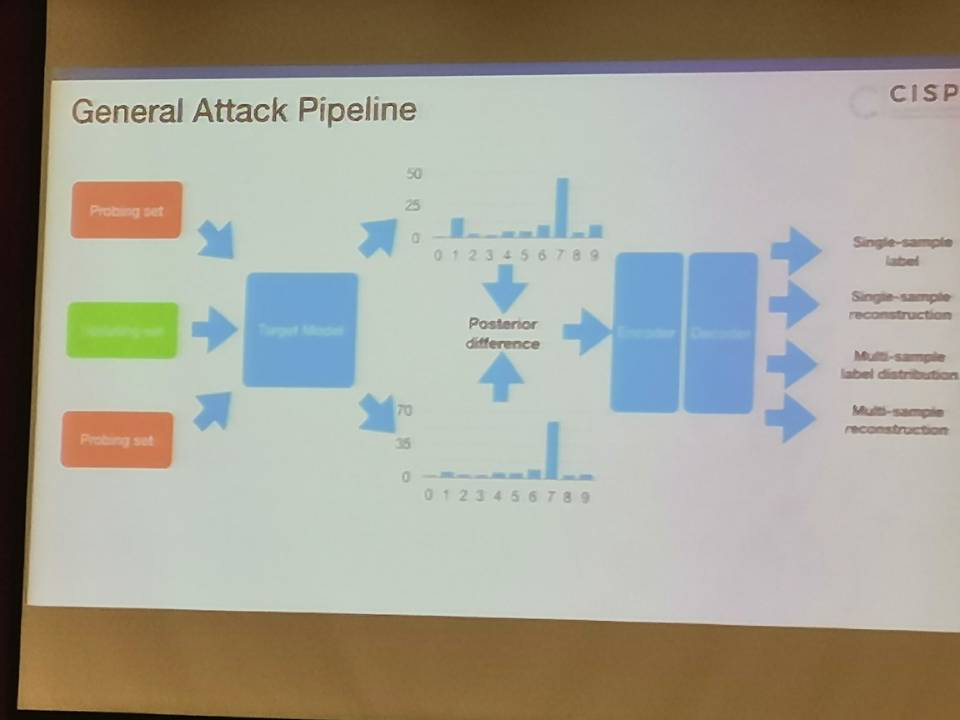
- Security
攻击者窃取模型
提问:GAN 通过模型产生数据,如何鉴别:收集足够的数据,标记并进行训练
语言理解之美——基于NLP的漏洞分析 王健强
学长首先讲解了栈溢出和堆溢出的区别。
以及检测漏洞的方法:动态:Fuzz、sanitizer;静态:模式匹配、符号执行、机器学习。
静态分析与动态分析的区别;自动化分析与手工代码审计。
目的:寻找非标准库中的/自定义的内存管理函数。现有工具无法识别
解决办法:使用NLP分析函数名,判断函数与内存管理的相关性。
使用NLP理解函数原型
分词、比较函数原型
分词演示:
比较:
Clang Static Analyzer
识别有较高的误报率,需要人工检查。
发现了vim和cpython中的double free、use after free